
LinkedIn recently updated their site including refreshing the look and feel of the user profiles. Although I'm a fan of the new design, the simple GreaseMonkey script that I wrote to facilitate adding publications to a user profile using PubMed IDs didn't survive the change. The script, which I originally wrote just to help my wife import her own publication list, must have proved useful to others since it's now been installed over two thousand times and I'm receiving complaints over its demise. OK, I can take a hint...
Introducing PubMed Importer v1.0
The PubMed importer is once again functional and available at userscripts.org. Since I was updating the script, I added Digital Object Identifier (DOI) lookups as well. Behind the scenes, the script pulls results from either PubMed or DOI.org depending on the format of the identifier entered by the user.
A couple of known shortcomings:
- Order of authors. LinkedIn always lists the owner of the user profile as the first author in the publication entry. Unfortunately, there's no way to change this. All other authors are imported by the tool in the order they appear in the PubMed or DOI data.
- Missing abstracts. The DOI results that I get back from DOI.org do not include abstracts and, in some cases, not even article titles. PubMed IDs will generally return a richer set of data.
If you find other issues, have suggested improvements, etc - please let me know by writing a comment below. If you find the script useful, please share with others through the "Share" links at the bottom.
Installation and Usage
To install the script:
- In Firefox, install the GreaseMonkey Firefox extension by going here and hitting "+ Add to Firefox". In Chrome, install the TamperMonkey extension by going here and hitting "Add to Chrome".
- Install the LinkedIn-PubMed ID Lookup script by going here and hitting "Install".
- Edit your profile on the LinkedIn site and click on the "+ Add" in the Publication section. This link will come immediately after your "Skills & Experience" section.
- A publication entry form should now appear on the page with a "PubMed ID or DOI" input box at the top of the form. Enter your id and hit the search button (magnifying glass). The form should be filled out with the publication information as acquired from PubMed or DOI.org. If you're happy with the results, hit submit. Otherwise, edit to your liking and hit submit.
Here are screen shots of what the LinkedIn page looks like before you open the form:

Here's the form before installing the script:
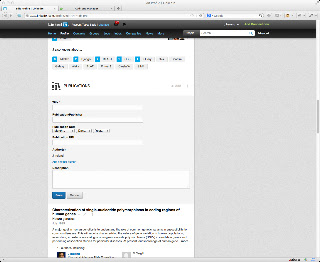
After the script has been installed...

And after a PubMed ID has been entered:
